-
Auto-contextualization, Not Attention
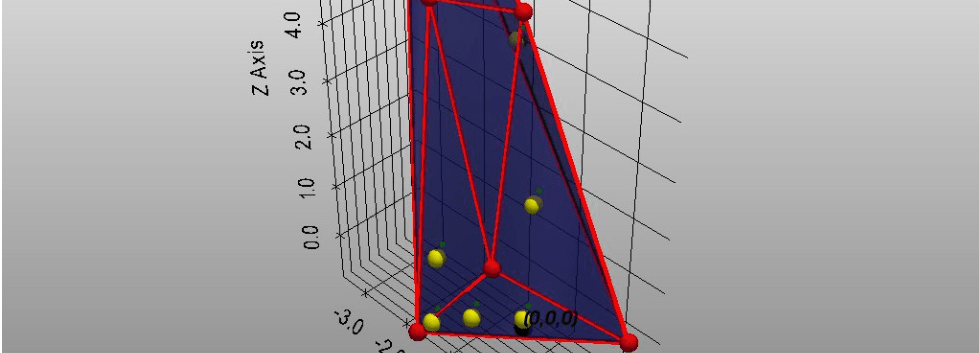
A computational geometric perspective on the elegant phenomenon behind GPT like, BERT like large language models and what makes them so powerful.
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
